





Parece que ChatGPT y OpenAI encontraron a su competencia: Gemini de Google. Esta nueva Inteligencia Artificial es el LLM (modelo grande de lenguaje) más grande, capaz y general que la compañía haya construido hasta la fecha. Te contamos los detalles ¡acá!

Google se puso la 10 y entró a la cancha para pelearle el primer lugar a OpenAI y su ChatGPT. ¿Cómo y con qué? Con la presentación oficial de su modelo grande de lenguaje más capaz hasta la fecha, Gemini. El director ejecutivo de Google y Alphabet, Sundar Pichai, anunció que éste es el primero de “una nueva generación de modelos de IA, inspirados en la forma en que las personas entienden e interactúan con el mundo”.
“Estamos dando el siguiente paso en nuestro viaje con Gemini, nuestro modelo más capaz y general hasta el momento, con un rendimiento de última generación en muchos puntos de referencia líderes. Nuestra primera versión, Gemini 1.0, está optimizada para diferentes tamaños: Ultra, Pro y Nano. Esta nueva era de modelos representa uno de los mayores esfuerzos de ciencia e ingeniería que hemos emprendido como empresa. Estoy realmente emocionado por lo que está por venir y por las oportunidades que Gemini desbloqueará para personas de todo el mundo”, escribió Pichai en una publicación de blog de Google.
En la misma publicación, Demis Hassabis, director ejecutivo y cofundador de Google DeepMind, escribió que Gemini es “el modelo más capaz y general” que construyeron junto a la división de Research. “Fue construido desde cero para ser multimodal, lo que significa que puede generalizar y comprender, operar y combinar sin problemas diferentes tipos de información, incluidos texto, código, audio, imagen y video”, explicó.
Como explican desde la compañía, el enfoque estándar para crear modelos multimodales implicaba entrenar componentes separados para diferentes modalidades y luego unirlos para imitar aproximadamente parte de esta funcionalidad. A veces, estos modelos pueden ser buenos para realizar determinadas tareas, como describir imágenes, pero tienen dificultades con un razonamiento más conceptual y complejo.

Es por esto que Google diseñó Gemini para que sea multimodal de forma nativa, previamente entrenado desde el principio en diferentes modalidades. Después, lo perfeccionaron con datos multimodales adicionales para mejorar su eficacia y así ayudarlo a “comprender y razonar perfectamente sobre todo tipo de entradas desde cero, mucho mejor que los modelos multimodales existentes, y sus capacidades son de última generación en casi todos los dominios”.
De esta manera, Gemini 1.0 puede ayudar a dar sentido a información visual y escrita compleja, extraer información de cientos de miles de documentos mediante la lectura, el filtrado y la comprensión de la información y reconocer y comprender texto, imágenes, audio y más al mismo tiempo. Así puede comprender mejor la información matizada y responder preguntas relacionadas con temas complicados, algo que podría servir para explicar el razonamiento en materias complejas como matemáticas y física, por ejemplo.

Pero esto no es todo. Géminis también puede codificar. Según informan en la publicación, la primera versión del modelo de Google puede “comprender, explicar y generar código de alta calidad en los lenguajes de programación más populares del mundo, como Python, Java, C++ y Go”.

La compañía incluso aprovechó una versión especializada de Gemini para crear un sistema de generación de código más avanzado, AlphaCode 2, que se destaca en la resolución de problemas de programación competitivos que van más allá de la codificación e involucran matemáticas complejas e informática teórica. Según Google, AlphaCode 2 resolvió casi el doble de problemas que su predecesor y estiman que funciona mejor que el 85% de los participantes de la competencia, en comparación con casi el 50% de AlphaCode.



Por otro lado, la compañía también mencionó que Gemini es su modelo más flexible hasta el momento, “capaz de ejecutarse de manera eficiente en todo, desde centros de datos hasta dispositivos móviles”. Sin embargo, para lograr esto, Google agregó que optimizaron su primera versión del modelo para tres tamaños diferentes: Nano (“el más eficiente para tareas en el dispositivo”), Pro (“mejor modelo para escalar en una amplia gama de tareas”) y Ultra (“el más grande y capaz para tareas altamente complejas”).


La compañía informó que llevarán Gemini al Pixel 8 Pro, el primer smartphone diseñado para ejecutar la versión Nano. En los próximos meses, esta tecnología estará disponible en más productos y servicios de Google, como Búsqueda, Anuncios, Chrome y Duet AI.
La versión Pro se integrará en Bard para “un razonamiento, planificación, comprensión más avanzados”, siendo esta la mayor actualización del chatbot de Google desde su lanzamiento. Estará disponible en inglés en más de 170 países y territorios, y planean expandirse a diferentes modalidades y admitir nuevos idiomas y ubicaciones en el futuro cercano. También se podrá acceder a las capacidades de Pro a través de la API de Geminis en Google AI Studio o Google Cloud Vertex AI.
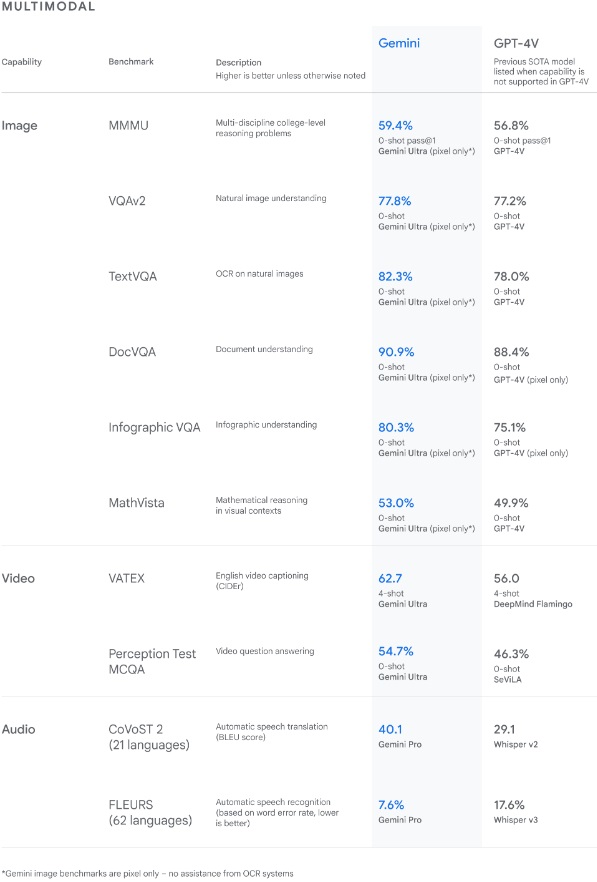
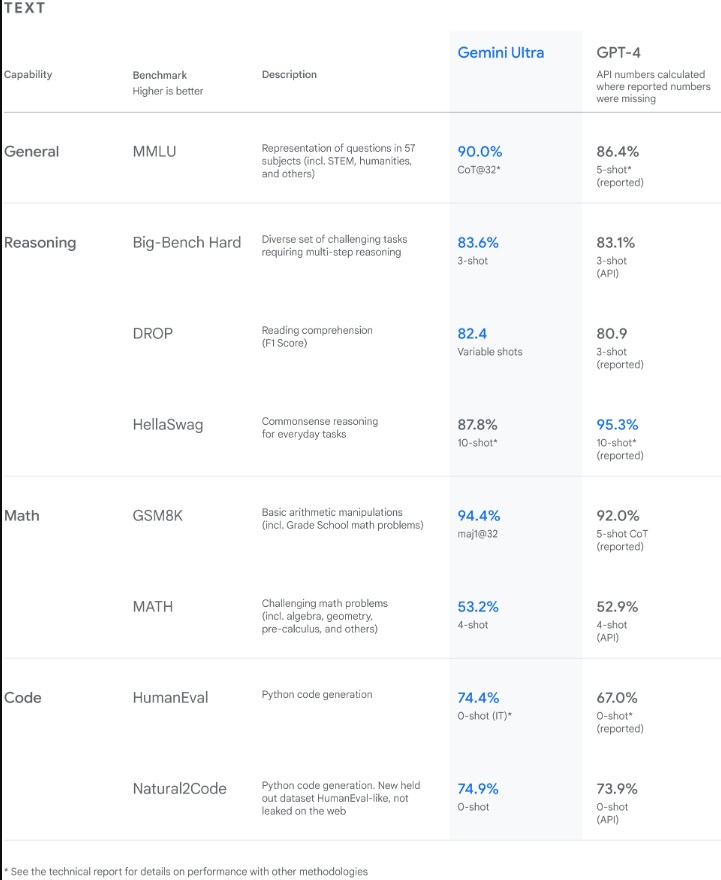
Mientras tanto, la versión Ultra, que no estará disponible al menos hasta 2024, obtuvo una puntuación más alta que cualquier otro modelo, incluido el GPT-4, en algunas pruebas comparativas. “Desde la comprensión de imágenes naturales, audio y video hasta el razonamiento matemático, el desempeño de Gemini Ultra supera los resultados actuales de última generación en 30 de los 32 puntos de referencia académicos ampliamente utilizados en la investigación y el desarrollo de modelos grande de lenguaje (LLM)”.
Es más, en la publicación Google especificó: “Con una puntuación del 90,0%, Gemini Ultra es el primer modelo que supera a los expertos humanos en MMLU (comprensión masiva de lenguajes multitarea), que utiliza una combinación de 57 materias como matemáticas, física, historia, derecho, medicina y ética para evaluar conocimientos y habilidades para la resolución de problemas”.
Además, agregaron: “Con los puntos de referencia de imágenes que probamos, Gemini Ultra superó a los modelos de última generación anteriores, sin la ayuda de sistemas de reconocimiento de caracteres (OCR) que extraen texto de imágenes para su posterior procesamiento. Estos puntos de referencia resaltan la multimodalidad nativa de Géminis e indican signos tempranos de las capacidades de razonamiento más complejas del modelo”.
A pesar de todo esto, Google todavía sigue completando comprobaciones de “confianza y seguridad, incluida la formación de equipos rojos por parte de partes externas confiables, y refinando aún más el modelo mediante ajustes y aprendizaje reforzado a partir de comentarios humanos (RLHF) antes de que esté disponible ampliamente”.
Es por esto que pondrán Gemini Ultra a disposición de clientes, desarrolladores, socios y expertos en seguridad y responsabilidad seleccionados para una experimentación temprana y comentarios antes de implementarlo a principios de 2024.

Para cerrar, Google también agregó que a principios del próximo año, lanzarán Bard Advanced, una nueva experiencia de IA de vanguardia que le brinda acceso a los “mejores modelos y capacidades” de la compañía, comenzando con Gemini Ultra.